
Azure Databricks
Apache Spark was developed in 2009 by researchers at the University of California, Berkeley. Their goal was to build a solution that overcame the inefficiencies of the Apache Hadoop MapReduce framework for big data processing activities. While based off of the MapReduce framework for distributing processing activities across several compute servers, Apache Spark enhances this framework by performing several operations in-memory. Spark also extends MapReduce by allowing users to interactively query data on the fly and create stream processing workflows.
The Spark architecture is very similar to the distributed pattern used by Hadoop. At a high level, Spark applications can be broken down into the following four components:
- A Spark driver that is responsible for dividing data processing operations into smaller tasks that are executed by the Spark executors. The Spark driver is also responsible for requesting compute resources from the cluster manager for the Spark executors. Clusters with multiple nodes host the Spark driver on the driver node.
- A Spark session is an entry point to Spark functionality. Establishing a Spark session allows users to work with the resilient distributed dataset (RDD) API and the Spark DataFrame API. These represent the low-level and high-level Spark APIs that developers can use to build Spark data structures.
- A cluster manager that is responsible for managing resource allocation for the cluster. Spark supports four types of cluster managers: the built-in cluster manager, Apache Hadoop YARN, Apache Mesos, and Kubernetes.
- A Spark executor that is assigned a task from the Spark driver and executes that task. Every worker node in a cluster is given its own Spark executor. Spark executors further parallelize work by assigning tasks to a slot on a node. The number of worker node slots are determined by the number of cores allocated to the node.
Figure 5.4 illustrates how the components of a Spark application fit into the architecture of a three node (one driver and two workers) Spark cluster.
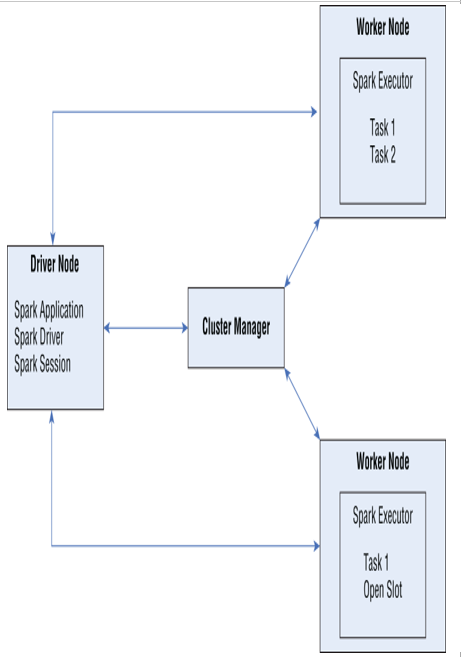
FIGURE 5.4 Apache Spark distributed architecture
The Spark Core API enables developers to build Spark applications with several popular development languages, including Java, Scala, Python, R, and SQL. These languages have Spark-specific APIs, like PySpark for Python and SparkR for R, that are designed to parallelize code operations across Spark executors. The creators of Spark also developed several Spark-based libraries designed for a variety of big data scenarios, including MLlib for distributed machine learning applications, GraphX for graph processing, Spark Structured Streaming for stream processing, and Spark SQL + DataFrames for structuring and analyzing data.
As mentioned earlier, the Spark RDD API and the Spark DataFrame API are used to create and manipulate data objects. The RDD API is a low-level API that serves as the foundation for Spark programming. An RDD is an immutable distributed collection of data, partitioned across multiple worker nodes. The RDD API has several operations that allow developers to perform transformations and actions in a parallelized manner. While the Spark DataFrame API is used more often than the Spark RDD API, there are still some scenarios where RDDs can be more optimal than DataFrames. More information on RDDs can be found at https://databricks.com/glossary/what-is-rdd.
The DataFrame API is a high-level abstraction of the RDD API that allows developers to use a query language like SQL to manipulate data. Unlike RDDs, DataFrame objects are organized as named columns (like a relational database table), making them easy to manipulate. DataFrames are also optimized with Spark’s native optimization engine, the catalyst optimizer, a feature that is not available for RDDs. More information on how to get started with the DataFrame API can be found at https://docs.microsoft.com/en-us/azure/databricks/getting-started/spark/dataframes.
Leave a Reply